
之前已经介绍了使用 Travily 来实现 AI 增强搜索功能,具体可以查看这篇文章:OpenClaw接入Tavily,增强AI搜索能力
今天介绍一款新的 AI 爬虫工具,它可以让本地 Agent 直接拥有专业级的网页抓取、站点映射、全站爬取和智能搜索能力。
OpenClaw + XCrawl 的完美集成,通过 4 个官方 Skill(xcrawl-scrape、xcrawl-map、xcrawl-crawl、xcrawl-search),让你的 OpenClaw 瞬间变身“网页专家”,无需额外部署云爬虫服务,也不用担心 IP 封禁和反爬机制。
本文手把手带你完成 OpenClaw 集成 XCrawl 的全流程配置,附带真实 Prompt 示例和避坑指南。读完这篇就能立即上手,大幅提升 Agent 的实战价值。
为什么选择 OpenClaw + XCrawl
- 一站式覆盖四大核心能力:单页抓取(Scrape)、站点 URL 发现(Map)、带边界爬取(Crawl)、精准搜索(Search),全部由 XCrawl 官方提供。
- 本地 Skill 零延迟:技能直接运行在你的 OpenClaw 环境中,数据不经过第三方中转,隐私更安全。
- 凭证统一管理:所有 Skill 共用
~/.xcrawl/config.json,无需每次 Prompt 重复输入 API Key。 - 输出标准化:返回结果尽量贴近 XCrawl 原生 API,便于后续审计和二次加工。
- 免费起步:注册 XCrawl 即可获得 1000 免费积分,足够日常开发测试。
- 权威支持:XCrawl 作为 2026 年 GitHub 上活跃度最高的爬虫 SDK 之一,文档完善,社区活跃,可靠性经过大量生产环境验证。
快速上手:4 步完成集成
步骤 1:准备前置条件
- 已安装最新版 OpenClaw
- 拥有 XCrawl API Key(前往 dash.xcrawl.com 注册,免费领 1000 积分)
- 本机已安装
curl和node
步骤 2:配置 XCrawl API Key
mkdir -p ~/.xcrawlcat > ~/.xcrawl/config.json <<'EOF'{ "XCRAWL_API_KEY": "你的真实_API_Key"}EOF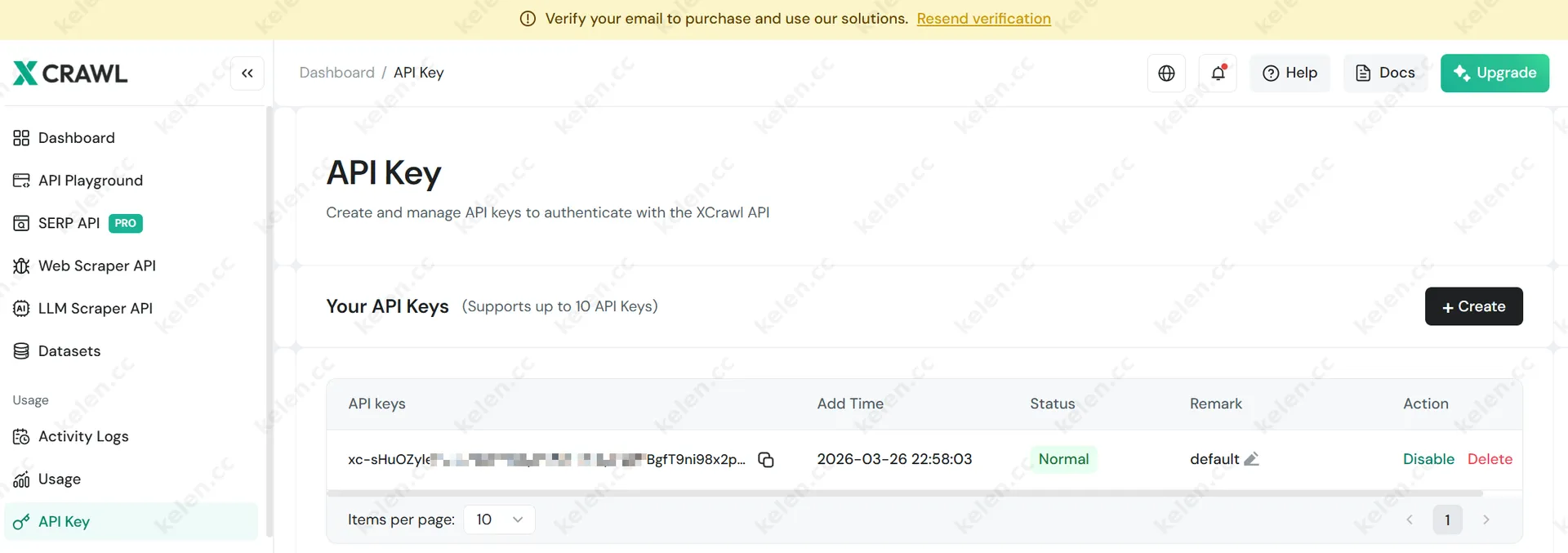
所有 XCrawl Skill 都会自动读取这个文件,安全又方便。
步骤 3:安装 XCrawl 官方 Skills
- 方案 A:机器全局安装(推荐)
git clone https://github.com/xcrawl-api/xcrawl-skills.gitmkdir -p ~/.openclaw/skillscp -R xcrawl-skills/skills/xcrawl-* ~/.openclaw/skills/- 方案 B:仅当前工作区安装
git clone https://github.com/xcrawl-api/xcrawl-skills.gitmkdir -p ./skillscp -R xcrawl-skills/skills/xcrawl-* ./skills/步骤 4:重启 OpenClaw
重新启动 OpenClaw 会话或刷新 Gateway,系统会自动扫描并加载新 Skills。完成后,在 Agent 对话中输入“列出可用技能”即可看到 4 个 xcrawl-* 技能。
四大 Skill 功能详解
| Skill | 主要用途 | 适用场景 | ClawHub 链接 |
|---|---|---|---|
| xcrawl-scrape | 单页面抓取(同步/异步),支持 Markdown/JSON/链接提取 | 快速阅读指定网页、提取结构化数据 | 查看详情 |
| xcrawl-map | 发现站点所有 URL 并规划爬取范围 | 站点调研、URL 收录 | 查看详情 |
| xcrawl-crawl | 带深度/数量限制的异步全站爬取 + 轮询 | 大型文档站、知识库爬取 | 查看详情 |
| xcrawl-search | 支持地域/语言控制的网页搜索 | 实时资讯采集、竞品分析 | 查看详情 |
💡 小技巧:如果希望 Agent 进一步总结内容,可在 Prompt 末尾加上:“抓取完成后用中文总结核心要点,并提取 5 个关键数据点。”
真实 Prompt 示例
单页抓取(最常用)
使用 xcrawl-scrape 以同步模式抓取 <https://example.com>,返回 Markdown 和链接。站点映射
使用 xcrawl-map 列出 <https://docs.xcrawl.com> 下仅 /docs/ 路径的 URL,限制 2000 条。全站爬取(异步轮询)
使用 xcrawl-crawl 对 <https://docs.xcrawl.com/doc/> 发起爬取任务,最大深度为 2,限制 100 条,然后轮询直到完成。精准搜索
使用 xcrawl-search 以中文搜索“2026 年最佳 AI Agent 工具”,限制返回 5 条结果,要求结果包含发布时间和来源链接。常见问题 & 避坑指南
| 问题 | 解决方案 |
|---|---|
| Skill 未出现? | 检查是否正确复制到 ~/.openclaw/skills/ 或工作区 ./skills/,并重启 OpenClaw。 |
| API Key 无效? | 确认 ~/.xcrawl/config.json 权限为 600,且 Key 未过期。 |
| 异步任务卡住? | xcrawl-scrape 和 xcrawl-crawl 支持异步,Agent 会自动创建任务并轮询,请在 Prompt 中明确要求“轮询直到完成”。 |
| 依赖缺失? | 确保本机有 curl 和 node,否则 Skill 会执行失败。 |
| 输出太原始? | 在 Prompt 中明确要求:“返回 Markdown 后用中文总结”即可实现二次加工。 |
立即行动
OpenClaw 集成 XCrawl 是目前最简单、最稳定、最符合生产需求的网页能力解决方案。只需要 10 分钟配置,你就能让本地 Agent 拥有媲美专业爬虫工具的实力,彻底告别“信息孤岛”。
立即行动:
- 注册 XCrawl 账号 领取免费 1000 积分
- 按照本文步骤完成集成
- 在 OpenClaw 中测试第一个 scrape Prompt
完成配置后,欢迎在评论区分享你的第一个成功案例!你是用它抓取文档、做竞品分析,还是自动化内容创作?我们一起交流优化技巧。




评论 按时间正序